
Ben and Jerry’s recently introduced a new flavor called Clusterfluff (now rebranded as the more politically correct What a Cluster), described as “peanut butter ice cream with caramel cluster pieces, peanut butter and marshmallow swirls”. Yummy. But today, let’s talk about a different cluster: SAP BusinessObjects Business Intelligence, also known as SAP BusinessObjects Enterprise.
 A cluster in SAP BusinessObjects Enterprise is defined as a system with multiple Central Management Servers (CMS) that work together by sharing a common system, or CMS, database. Each CMS is typically on its own physical device, known as a node. SAP BusinessObjects enthusiasts who take the BOE330 training class, Designing and Deploying a Solution, get to team up with their fellow students and create clusters in class. Let’s discuss using Microsoft Windows; however, the same principles apply to Linux/Unix.
A cluster in SAP BusinessObjects Enterprise is defined as a system with multiple Central Management Servers (CMS) that work together by sharing a common system, or CMS, database. Each CMS is typically on its own physical device, known as a node. SAP BusinessObjects enthusiasts who take the BOE330 training class, Designing and Deploying a Solution, get to team up with their fellow students and create clusters in class. Let’s discuss using Microsoft Windows; however, the same principles apply to Linux/Unix.
I recently encountered a BI system with a poorly devised cluster. It was the second time that I’ve seen this ill-advised configuration on the XI platform, so it seemed worth writing about. Especially since SAP BusinessObjects Business Intelligence 4 continues the server architecture of the past few versions. In both of my situations, each physical server, or node, was built with a “new” install. Once the installation was completed, the second CMS was stopped and reconfigured to point to the same system database as the first CMS, as shown in the illustration below (click image to enlarge).
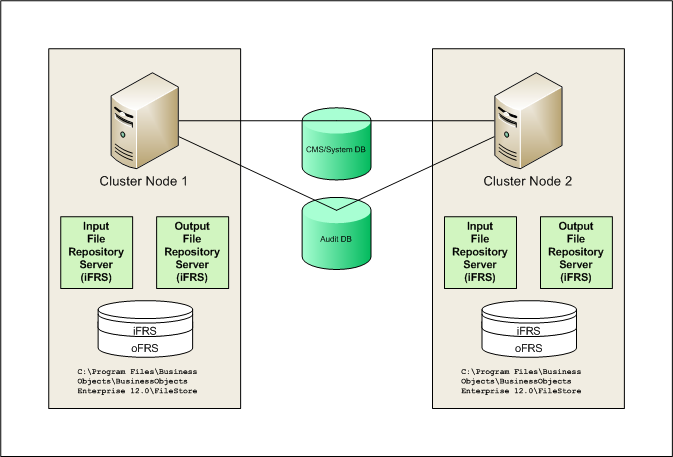
Each node has an identical configuration. There’s two of everything. Two Central Management Servers. Two Crystal Reports Processing Servers. Two Web Intelligence Processing Servers. And, sigh, two Input File Repository Servers, or iFRS. There are two Output File Repository Servers, or oFRS, as well. Each file repository server points to local storage on the node, which is a significant flaw that could lead to corruption of the cluster.
In a SAP BusinessObjects cluster, only one FRS is actively working even when all FRS in the cluster are enabled. Just like many of your coworkers, the rest of the FRS sit around doing nothing in a passive state waiting for the active FRS to fail. All FRS connect with the CMS upon startup. The active FRS is the one that contacts the CMS first.
So how can the cluster become corrupted? Let’s assume that the iFRS on node 1 becomes active. When a report is published to the system, it is stored on the iFRS default location, which is the C: drive on node 1. The CMS database contains an InfoObject containing the physical path to the report.
Next, let’s assume that the iFRS on node 1 fails. The iFRS on node 2 becomes active. When Wanda in accounting logs into InfoView to view a month-end report, the processing server will fetch the report from the active iFRS on node 2. However, because the report was originally written to the C: drive on node 1, Wanda will receive an error and call the Business Intelligence help desk.
The cluster, sadly, has become fluffed.
A better solution would be to disable the iFRS and oFRS on node 2, guaranteeing that the iFRS and oFRS on node 1 are always active and that all documents are stored locally on node 1. This configuration is shown in the following illustration (click image to enlarge).
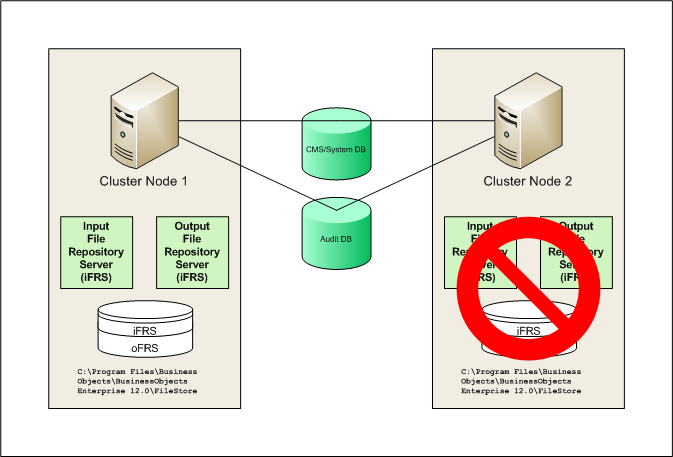
You might argue that this configuration is not fault tolerant. And it isn’t. However, neither was the first configuration. Disabling the second iFRS and oFRS is the first step to preventing additional corruption.
The best solution is to create a file system that both nodes can share, as shown in the illustration below (click image to enlarge).
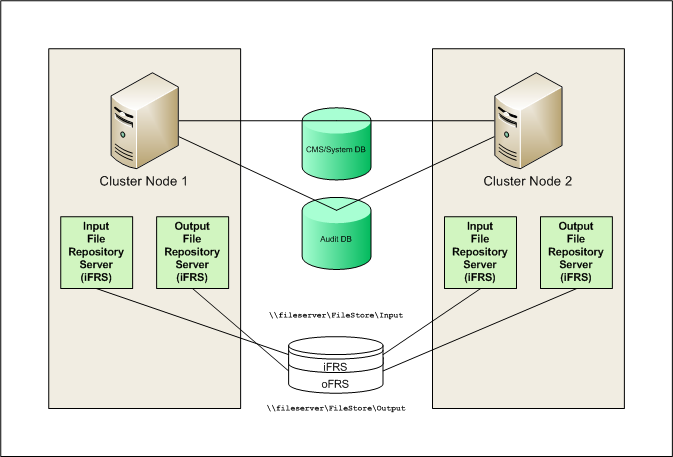 Each FRS is configured in the Central Management Console (CMC) to use the shared space, typically by specifying a UNC path. Since the shared space is on a different device, the File Repository Servers will need to run using a domain account rather than the default Microsoft Windows Local System account. This account is specified in the Central Configuration Manager (CCM), either directly on the File Repository Server (XI R2) or vicariously through the SIA (XI 3.x, BI 4.0, BI 4.1). Be sure that separate directories are created to distinguish the Input File Repository from the Output File Repository; however, both can share a common parent directory, as they do in the default out-of-the-box configuration.
Each FRS is configured in the Central Management Console (CMC) to use the shared space, typically by specifying a UNC path. Since the shared space is on a different device, the File Repository Servers will need to run using a domain account rather than the default Microsoft Windows Local System account. This account is specified in the Central Configuration Manager (CCM), either directly on the File Repository Server (XI R2) or vicariously through the SIA (XI 3.x, BI 4.0, BI 4.1). Be sure that separate directories are created to distinguish the Input File Repository from the Output File Repository; however, both can share a common parent directory, as they do in the default out-of-the-box configuration.
There are other design considerations for a truly fault-tolerant BI architecture, such as failover in the web application server tier. But that will have to wait until a future discussion. In the meantime, I hope you will enjoy a pint of Ben and Jerry’s Clusterfluff ice cream. And inspect your BI system to insure proper configuration.
Resources
SAP KB 1378753 – How to configure the File Repository Server (FRS) to point to the Network Attached Storage (NAS)?
What are your experiences with SAP BusinessObjects clustering? Share your thoughts (and favorite bookmarks).
| BOE330 |
B



Thanks for this info. We don’t have a clustered BOE, but we are considering the clustered solution. Could you provide some links to information about BOE clustering?
Thanks for writing detailed article.
We have similar setup with NAS drive.
One flaw which i see in this setup is that multiple CMS may or can cause deadlock situation or on node where CMS is there should not be webi report server or job server. because CMS like a heart beat needs to constantly communicate with repository and webi/job servers may cause interruption.
Just learned that Ben & Jerry’s has renamed “Clusterfluff” to “What a Cluster”. Must have been too controversial.
In a CMS cluster scenario, how does Tomcat decide which CMS to communicate to? Is it always the same CMS?
Mohanraj,
I think this topic on the BusinessObjects Board will help you.
Regards,
Dallas
Dallas,
very good article. I am in the middle of setting up a cluster for BOE 4.0 and your article makes all sense.
I am stuck at the last comment in your article: The best solution is to create a file system that both nodes can share. How do we achieve that in a windows environment where all our storage is SAN attached. My windows admin says that the only way to do so is to attach this storage to server 1 and then share it to server 2 as a mapped network drive. However, that would not work again if server 1 goes down. So, what is the other solution to share a storage among 2 servers at all times. I need to put my windows/network admin on the right path.
Thanks,
BV
BV,
I’m not a Windows admin, but if it were me I would allocate storage on a third server (server 3) then map it either via UNC or drive letter to each iFRS, ex. \server3Input. Then do the same thing for the oFRS, \server3Output. The important thing to understand is that all of the iFRS’s need to point to a SINGLE directory structure. And all of the oFRS’s need to point to a single directory structure SEPARATE from the one used for iFRS. Good luck!
I am struck on cluster, i am setting up on sun solaris. I hv 3rd sever with oracle database 11g for cms / audit db. Also created filesystem as NFS with the name filestore under this frsinput & frsoutput folder has been created.
Also we hv created 2nd server as custom installation option not as new installation. Then 2 server ifrs & ofrs service has been maped filesystem storage location as follow \filestore/frsinput and frsoutput. Kindly advice we hv done the right setup for cluster. +965 99811869
RC,
Thanks for writing but unfortunately I cannot provide technical support. Take a look here for tips on getting answers.
Regards,
Dallas
Hi Prasad,
Your setup seems right and should be okay. Just make sure in the SIA properties, the cluster name has come as a common one.
Also, an additional test of users connecting to the 2nd machine and creating reports, exporting them to repository. These reports should then be visible and refreshable on the 1st server and vice versa.
Additionally, having a proper load balancing device (like netscaler) will help in distributing the load, though BO would take care of it internally.
Regards,
George
Hi Dallas
May I know what is the correct way to disable iFRS & oFRS in Node 2 ?
Stop & Disable “SIA.InputFileRepository” & “OutputFileRepository” services ?
Also untick “Automatically start” for both above services ?
We’re still waiting our vendor to prepare NAS storage for us.
You’ve got it. Stop, disable, then uncheck automatically restart.
Hi Dallas,
Could you please provide high level documentation on Installation and clustering on solaris environment.
Thanks,
R
R, Please check the SAP BusinessObjects administrator’s guide on the SAP Help Portal, http://help.sap.com/
Hi,
We are facing the exact same issue, since there is an individual FRS in each node. As a remedial situation, we are looking at going for a shared server set up. My question is, I have files in both iFRS with same file directory names. So when i move them to the new file server, how would that work? Will we loose some content?
Thanks
V
V,
Thanks for writing.
The danger in attempting to merge two distinct file repositories is that both may contain a particular infoobject and how will you insure the merged repository contains the most recent update?
I recommend that you open a case with SAP and let them advise you the best way to recover from your current configuration.
Hi Marks, Good article.
I have a question. What do you think about 2 nodes with all tiers (App + Intelligence + Processing) installed and running?
Ideally the App tier should be seperate. But for easy maintenance, I am thinking about all BO tiers on 2 nodes (2 seperate servers). Each node will have enough capacity to run all 3 tiers. This is for a high availablity system.
Thanks,
Prasad
Prassad,
Thank you for your question. We have successfully combined the intelligence + processing tiers on a single node, assuming that node is sufficiently large. For example, we have 2 identical nodes clustered together, each having 96 GB RAM. But we still have Tomcat on two smaller, separate (and load balanced) servers. I do not recommend Tomcat on same machine for production servers.
Regards,
Dallas
Good pointer to a common fault. I must say though that in recent attempts the ‘2 server new then reconnect’ procedure seems easier/less fault prone than the ‘extend’ installation.
Quite often I also find that general fault tolerance best practise is not followed, and even when the FRS has been pointed at a shared folder, that itself is on a single device and is not fault tolerant – same with the CMS database.
If you’re doing this out there, don’t forget to remove ALL single points of failure!
Phil,
Great advice about fault tolerance. Thanks for writing!
Dallas
I wish I found this blog sooner! I’m currently having an issue with a dual node setup and SSO. My SSO works for each individual server just fine, however when using a DNS alias it cannot auto login the BI page. Any thoughts or direction would be appreciated.
Example:
server1.domain.com:8080/BOE/BI – works with no problem auto sign on
server2.domain.com:8080/BOE/BI – works with no problem auto sign on
DNS alias: devreports.domain.com:8080/BOE/BI – does not work
Not quite sure what I’m missing. Thank you.
Shawhan,
Thanks for writing. I haven’t written much on the topic but you have to run setspn commands for the load balancer/alias just like you do for the individual web servers. SAP has pretty good documentation on SSO sign-up, and pretty fast response on these types of issues if you open a support incident.
Dallas
Thank you Dallas, This has been resolved!